Для задоволення потреб хмарних сервісів мережа поступово поділяється на Underlay та Overlay. Underlay-мережа – це фізичне обладнання, таке як маршрутизація та комутація в традиційному центрі обробки даних, яке все ще вірить у концепцію стабільності та забезпечує надійні можливості передачі даних по мережі. Overlay – це бізнес-мережа, інкапсульована в ній, ближче до сервісу, через інкапсуляцію протоколу VXLAN або GRE, щоб забезпечити користувачам прості у використанні мережеві сервіси. Underlay-мережа та Ooverlay-мережа є пов'язаними та відокремленими, вони пов'язані одна з одною та можуть розвиватися незалежно.
Підлегла мережа є основою мережі. Якщо підлегла мережа нестабільна, для бізнесу немає угоди про рівень обслуговування (SLA). Після трирівневої архітектури мережі та архітектури мережі Fat-Tree, архітектура мережі центру обробки даних переходить до архітектури Spine-Leaf, що започаткувало третє застосування мережевої моделі CLOS.
Традиційна мережева архітектура центру обробки даних
Тришаровий дизайн
З 2004 по 2007 рік трирівнева мережева архітектура була дуже популярною в центрах обробки даних. Вона має три рівні: базовий рівень (високошвидкісна комутаційна магістраль мережі), рівень агрегації (який забезпечує підключення на основі політик) та рівень доступу (який підключає робочі станції до мережі). Модель виглядає наступним чином:
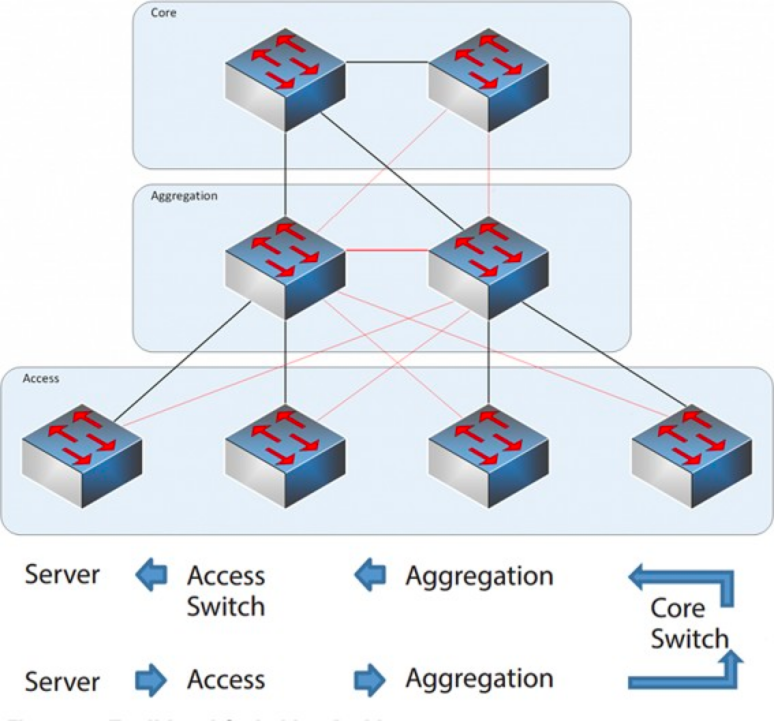
Тришарова мережева архітектура
Базовий рівень: Базові комутатори забезпечують високошвидкісну пересилку пакетів до та з центру обробки даних, підключення до кількох рівнів агрегації та стійку мережу маршрутизації L3, яка зазвичай обслуговує всю мережу.
Рівень агрегації: Комутатор агрегації підключається до комутатора доступу та надає інші послуги, такі як брандмауер, розвантаження SSL, виявлення вторгнень, аналіз мережі тощо.
Рівень доступу: Комутатори доступу зазвичай розташовані у верхній частині стійки, тому їх також називають комутаторами ToR (Top of Rack), і вони фізично підключаються до серверів.
Зазвичай, комутатор агрегації є точкою розмежування між мережами L2 та L3: мережа L2 розташована нижче комутатора агрегації, а мережа L3 — вище. Кожна група комутаторів агрегації керує точкою доставки (POD), і кожен POD є незалежною мережею VLAN.
Протокол мережевого циклу та охоплюючого дерева
Утворення петель здебільшого спричинене плутаниною, спричиненою нечіткими шляхами призначення. Коли користувачі будують мережі, для забезпечення надійності вони зазвичай використовують резервні пристрої та резервні з'єднання, що неминуче призводить до утворення петель. Мережа другого рівня знаходиться в одному домені широкомовлення, і широкомовні пакети будуть передаватися неодноразово в петлі, утворюючи широкомовний шторм, який може миттєво спричинити блокування портів та параліч обладнання. Тому, щоб запобігти широкомовним штормам, необхідно запобігати утворенню петель.
Щоб запобігти утворенню петель та забезпечити надійність, можна перетворити резервні пристрої та резервні з'єднання лише на резервні пристрої та резервні з'єднання. Тобто, резервні порти та з'єднання пристроїв за нормальних обставин блокуються та не беруть участі в пересиланні пакетів даних. Лише тоді, коли поточний пристрій пересилання, порт або з'єднання виходять з ладу, що призводить до перевантаження мережі, резервні порти та з'єднання пристроїв будуть відкриті, щоб мережу можна було відновити до нормального стану. Це автоматичне керування реалізовано протоколом STP (Spanning Tree Protocol).
Протокол охоплюючого дерева працює між рівнем доступу та рівнем приймача, і в його основі лежить алгоритм охоплюючого дерева, що працює на кожному мосту з підтримкою STP, який спеціально розроблений для уникнення петель мостів за наявності надлишкових шляхів. STP вибирає найкращий шлях даних для пересилання повідомлень і забороняє ті з'єднання, які не є частиною охоплюючого дерева, залишаючи лише один активний шлях між будь-якими двома вузлами мережі, а інше висхідне з'єднання буде заблоковано.
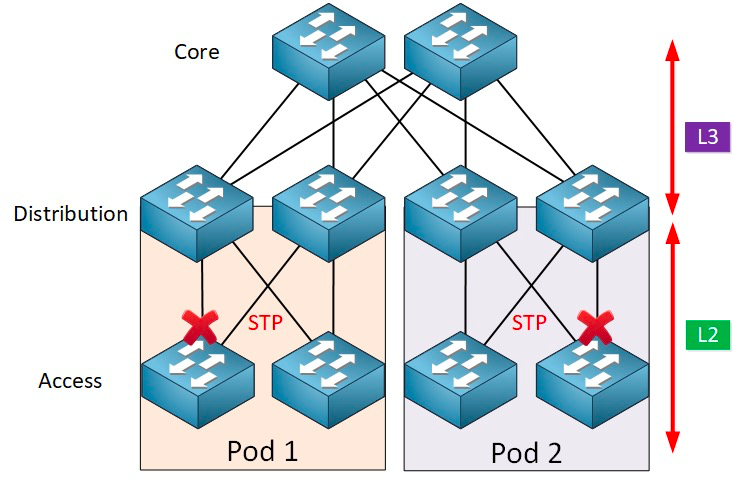
STP має багато переваг: він простий, plug-and-play та вимагає дуже мало налаштування. Машини в кожному pod належать до однієї VLAN, тому сервер може довільно переносити розташування в межах pod без зміни IP-адреси та шлюзу.
Однак, паралельні шляхи переадресації не можуть використовуватися протоколом STP, що завжди призведе до відключення надлишкових шляхів у VLAN. Недоліки STP:
1. Повільна конвергенція топології. Коли змінюється топологія мережі, протоколу охоплюючого дерева потрібно 50-52 секунди для завершення конвергенції топології.
2, не може забезпечити функцію балансування навантаження. Коли в мережі є петля, протокол Spanning Tree може лише блокувати петлю, щоб з'єднання не могло пересилати пакети даних, витрачаючи мережеві ресурси.
Віртуалізація та проблеми східно-західного трафіку
Після 2010 року, щоб покращити використання обчислювальних ресурсів та ресурсів зберігання даних, центри обробки даних почали впроваджувати технологію віртуалізації, і в мережі почала з'являтися велика кількість віртуальних машин. Віртуальна технологія перетворює сервер на кілька логічних серверів, кожна віртуальна машина може працювати незалежно, має власну ОС, програму, власну незалежну MAC-адресу та IP-адресу, і вони підключаються до зовнішньої сутності через віртуальний комутатор (vSwitch) всередині сервера.
Віртуалізація має супутню вимогу: міграцію віртуальних машин у реальному часі, можливість переміщення системи віртуальних машин з одного фізичного сервера на інший, зберігаючи при цьому нормальну роботу служб на віртуальних машинах. Цей процес нечутливий до кінцевих користувачів, адміністратори можуть гнучко розподіляти ресурси сервера або ремонтувати та оновлювати фізичні сервери, не впливаючи на нормальне використання користувачами.
Щоб забезпечити безперебійну роботу сервісу під час міграції, необхідно, щоб не лише IP-адреса віртуальної машини залишалася незмінною, але й щоб під час міграції зберігався її робочий стан (наприклад, стан TCP-сеансу). Тому динамічна міграція віртуальної машини може виконуватися лише в одному домені другого рівня, але не в межах домену другого рівня. Це створює потребу в більших доменах другого рівня, від рівня доступу до основного рівня.
Точка розділу між L2 та L3 у традиційній великій мережевій архітектурі другого рівня знаходиться на центральному комутаторі, а центр обробки даних під центральним комутатором є повноцінним доменом широкомовлення, тобто мережею L2. Таким чином, можна реалізувати довільне розгортання пристроїв та міграцію місцезнаходження, і не потрібно змінювати конфігурацію IP та шлюзу. Різні мережі L2 (VLans) маршрутизуються через центральні комутатори. Однак центральний комутатор у цій архітектурі повинен підтримувати величезну таблицю MAC та ARP, що висуває високі вимоги до можливостей центрального комутатора. Крім того, комутатор доступу (TOR) також обмежує масштаб всієї мережі. Це зрештою обмежує масштаб мережі, розширення мережі та її еластичність, а проблема затримки на трьох рівнях планування не може задовольнити потреби майбутнього бізнесу.
З іншого боку, східно-західний трафік, що виникає внаслідок технології віртуалізації, також створює проблеми для традиційної трирівневої мережі. Трафік центрів обробки даних можна умовно розділити на такі категорії:
Рух транспорту з півночі на південь:Трафік між клієнтами поза центром обробки даних та сервером центру обробки даних або трафік із сервера центру обробки даних до Інтернету.
Рух транспорту схід-захід:Трафік між серверами всередині центру обробки даних, а також трафік між різними центрами обробки даних, наприклад, аварійне відновлення між центрами обробки даних, зв'язок між приватними та публічними хмарами.
Впровадження технології віртуалізації робить розгортання додатків все більш розподіленим, а «побічним ефектом» є збільшення трафіку схід-захід.
Традиційні трирівневі архітектури зазвичай розроблені для трафіку Північ-Південь.Хоча його можна використовувати для руху транспорту зі сходу на захід, зрештою він може не виконувати свої функції належним чином.
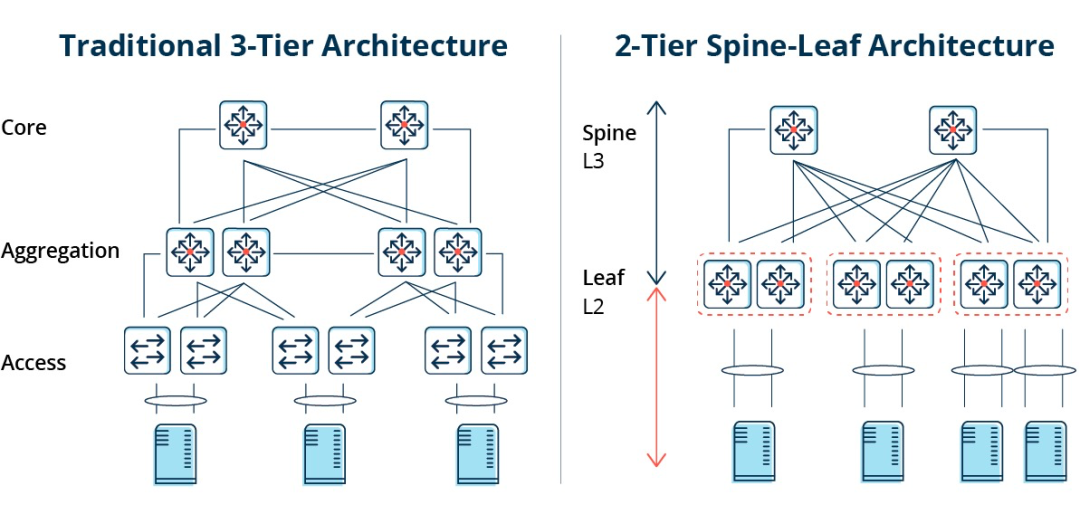
Традиційна трирівнева архітектура проти архітектури Spine-Leaf
У трирівневій архітектурі трафік схід-захід має пересилатися через пристрої на рівнях агрегації та ядра. Без потреби, проходячи через багато вузлів. (Сервер -> Доступ -> Агрегація -> Основний комутатор -> Агрегація -> Комутатор доступу -> Сервер)
Таким чином, якщо великий обсяг східно-західного трафіку проходить через традиційну трирівневу мережеву архітектуру, пристрої, підключені до одного й того ж порту комутатора, можуть конкурувати за пропускну здатність, що призводить до низького часу відгуку кінцевих користувачів.
Недоліки традиційної тришарової мережевої архітектури
Можна побачити, що традиційна трирівнева архітектура мережі має багато недоліків:
Втрата пропускної здатності:Щоб запобігти зацикленню, протокол STP зазвичай працює між рівнем агрегації та рівнем доступу, так що лише один висхідний канал комутатора доступу фактично передає трафік, а інші висхідні канали будуть заблоковані, що призведе до втрати пропускної здатності.
Складність розміщення великомасштабної мережі:З розширенням масштабу мережі, центри обробки даних розподіляються по різних географічних місцях, віртуальні машини необхідно створювати та мігрувати куди завгодно, а їхні мережеві атрибути, такі як IP-адреси та шлюзи, залишаються незмінними, що вимагає підтримки fat Layer 2. У традиційній структурі міграцію виконати неможливо.
Відсутність руху транспорту зі сходу на захід:Трирівнева мережева архітектура в основному розроблена для трафіку Північ-Південь, хоча вона також підтримує трафік Схід-Захід, але недоліки очевидні. Коли трафік Схід-Захід великий, навантаження на комутатори рівня агрегації та основного рівня значно зростає, а розмір та продуктивність мережі обмежуються рівнем агрегації та основним рівнем.
Через це підприємства стикаються з дилемою вартості та масштабованості:Підтримка масштабних високопродуктивних мереж вимагає великої кількості обладнання конвергенційного та основного рівнів, що не лише призводить до високих витрат для підприємств, але й вимагає попереднього планування мережі під час її побудови. Невеликий масштаб мережі призводить до марнування ресурсів, а зростаючий масштаб мережі ускладнює її розширення.
Архітектура мережі Spine-Leaf
Що таке архітектура мережі Spine-Leaf?
У відповідь на вищезазначені проблеми,З'явився новий дизайн центрів обробки даних, архітектура мережі Spine-Leaf, яку ми називаємо мережею Leaf-Leaf.
Як випливає з назви, архітектура має хребетний шар та листовий шар, включаючи хребетні комутатори та листові комутатори.
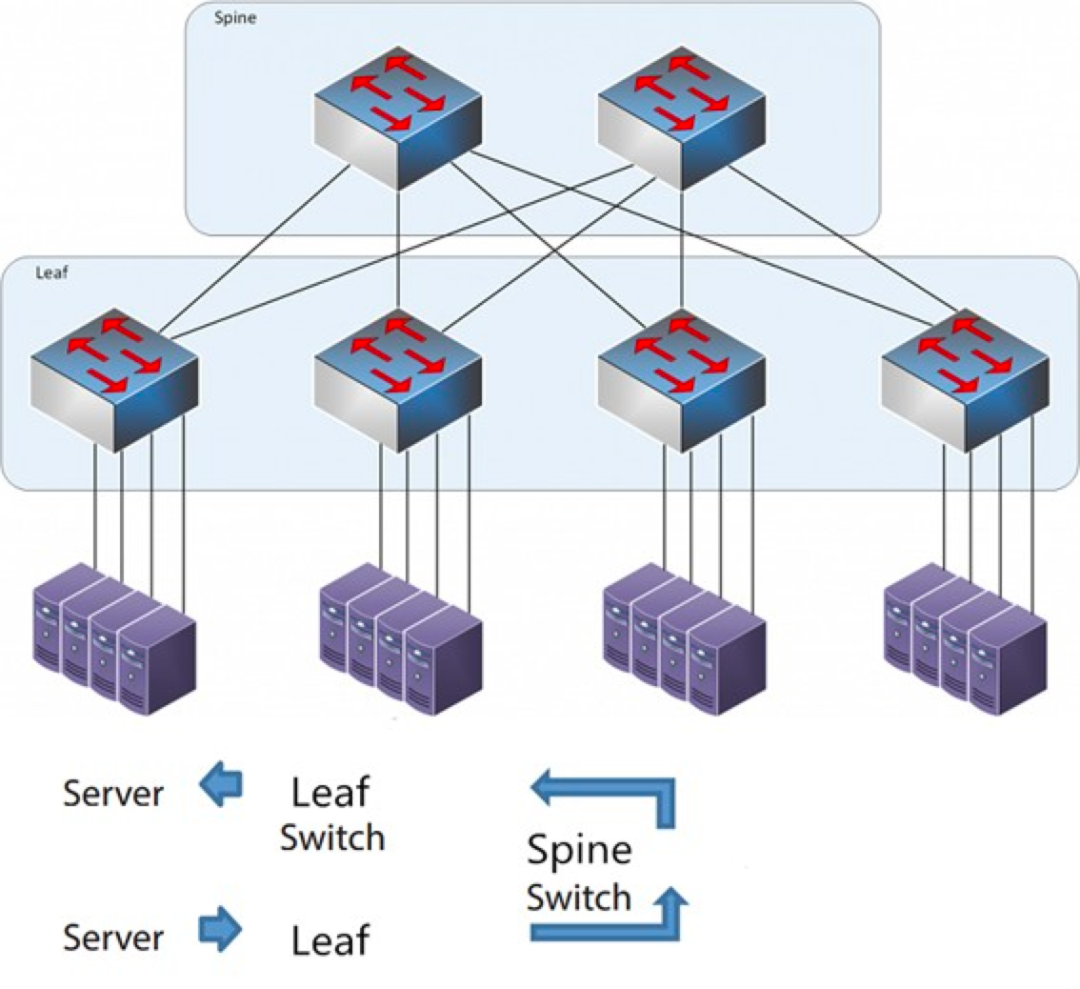
Архітектура хребта та листя
Кожен листовий комутатор підключений до всіх гребеневих комутаторів, які не з'єднані безпосередньо один з одним, утворюючи повномерну топологію.
У схемі «хребет і лист» з'єднання від одного сервера до іншого проходить через однакову кількість пристроїв (Сервер -> Лист -> Хребетний комутатор -> Листовий комутатор -> Сервер), що забезпечує передбачувану затримку. Оскільки пакету потрібно пройти лише через один хребет та інший лист, щоб досягти пункту призначення.
Як працює Spine-Leaf?
Leaf Switch: Він еквівалентний комутатору доступу в традиційній трирівневій архітектурі та безпосередньо підключається до фізичного сервера як TOR (Top Of Rack). Різниця з комутатором доступу полягає в тому, що точка розмежування мережі L2/L3 тепер знаходиться на Leaf-комутаторі. Leaf-комутатор знаходиться над трирівневою мережею, а Leaf-комутатор — під незалежним доменом широкомовлення L2, що вирішує проблему BUM великої дворівневої мережі. Якщо двом Leaf-серверам потрібно зв'язатися, їм потрібно використовувати маршрутизацію L3 та пересилати її через Spine-комутатор.
Комутатор Spine: Еквівалент основного комутатора. ECMP (Equal Cost Multi Path - багатошляхова мережа з однаковою вартістю) використовується для динамічного вибору кількох шляхів між комутаторами Spine та Leaf. Різниця полягає в тому, що Spine тепер просто забезпечує стійку мережу маршрутизації L3 для комутатора Leaf, тому північно-південний трафік центру обробки даних може маршрутизуватися з комутатора Spine, а не безпосередньо. Північно-південний трафік може маршрутизуватися з граничного комутатора паралельно до комутатора Leaf до маршрутизатора WAN.
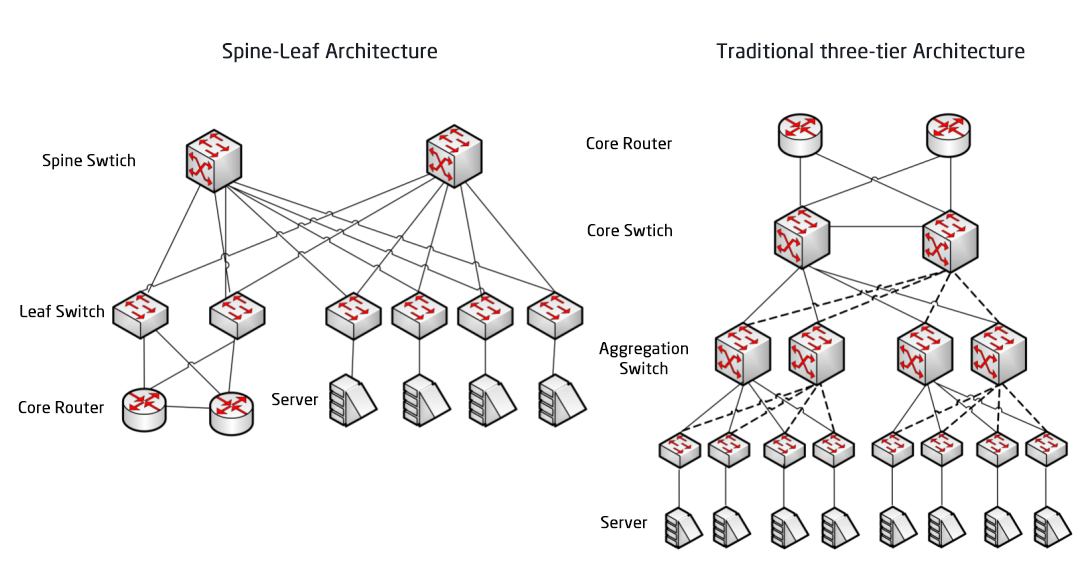
Порівняння архітектури мережі Spine/Leaf та традиційної тришарової архітектури мережі
Переваги Spine-Leaf
Квартира:Плоский дизайн скорочує шлях зв'язку між серверами, що призводить до меншої затримки, що може значно покращити продуктивність програм і сервісів.
Гарна масштабованість:Коли пропускної здатності недостатньо, збільшення кількості грядових комутаторів може горизонтально розширити пропускну здатність. Коли кількість серверів збільшується, ми можемо додати кінцеві комутатори, якщо щільність портів недостатня.
Зниження витрат: Трафік у північному та південному напрямках, що виходить або з кінцевих вузлів, або з вершинних вузлів. Потік схід-захід, розподілений по кількох шляхах. Таким чином, мережа кінцевого типу може використовувати комутатори фіксованої конфігурації без необхідності використання дорогих модульних комутаторів, що зменшує витрати.
Низька затримка та уникнення перевантажень:Потоки даних у мережі Leaf Ridge мають однакову кількість переходів по мережі незалежно від джерела та пункту призначення, і будь-які два сервери є досяжними один з одного через три переходи Leaf - >Spine - >Leaf. Це встановлює більш прямий шлях трафіку, що покращує продуктивність та зменшує вузькі місця.
Висока безпека та доступність:Протокол STP використовується в традиційній трирівневій мережевій архітектурі, і коли пристрій виходить з ладу, він повторно збігається, що впливає на продуктивність мережі або навіть призводить до її збою. В архітектурі типу «лист-гребень», коли пристрій виходить з ладу, немає потреби в повторній збіганні, і трафік продовжує проходити іншими звичайними шляхами. З'єднання з мережею не змінюється, а пропускна здатність зменшується лише на один шлях, що незначно впливає на продуктивність.
Балансування навантаження через ECMP добре підходить для середовищ, де використовуються централізовані платформи управління мережею, такі як SDN. SDN дозволяє спростити налаштування, керування та перенаправлення трафіку у разі блокування або збою з'єднання, що робить інтелектуальне балансування навантаження з повною топологією mesh відносно простим способом налаштування та керування.
Однак, архітектура Spine-Leaf має деякі обмеження:
Одним з недоліків є те, що кількість комутаторів збільшує розмір мережі. Центр обробки даних з архітектурою мережі типу «ліво-гребень» повинен збільшувати кількість комутаторів та мережевого обладнання пропорційно кількості клієнтів. Зі збільшенням кількості хостів потрібна велика кількість комутаторів типу «ліво-гребень» для з'єднання з комутатором типу «гребень».
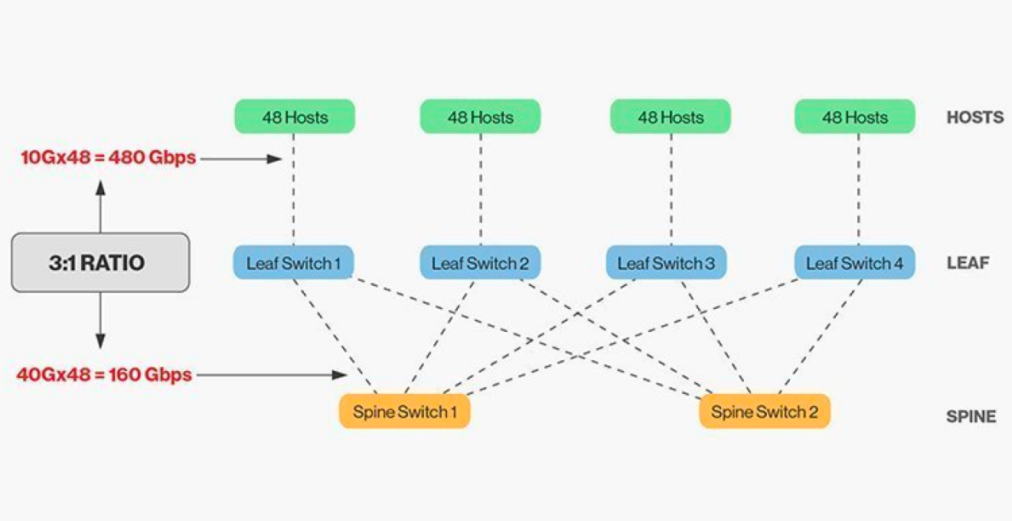
Пряме з'єднання гребеневих та гребеневих комутаторів вимагає узгодження, і загалом, розумне співвідношення пропускної здатності між гребеневими та гребеневими комутаторами не може перевищувати 3:1.
Наприклад, на кінцевому комутаторі є 48 клієнтів зі швидкістю 10 Гбіт/с із загальною пропускною здатністю портів 480 Гбіт/с. Якщо чотири порти висхідного каналу 40 Гбіт/с кожного кінцевого комутатора підключені до грядкового комутатора 40 Гбіт/с, він матиме пропускну здатність висхідного каналу 160 Гбіт/с. Співвідношення становить 480:160, або 3:1. Вихідні канали центрів обробки даних зазвичай мають пропускну здатність 40 Гбіт/с або 100 Гбіт/с і можуть з часом переноситися з початкової точки 40 Гбіт/с (Nx 40 Гбіт/с) до 100 Гбіт/с (Nx 100 Гбіт/с). Важливо зазначити, що висхідний канал завжди повинен працювати швидше, ніж низхідний, щоб не блокувати канал портів.
Мережі Spine-Leaf також мають чіткі вимоги до проводки. Оскільки кожен кінцевий вузол має бути підключений до кожного хребтового комутатора, нам потрібно прокладати більше мідних або оптоволоконних кабелів. Відстань міжз'єднання збільшує вартість. Залежно від відстані між взаємопов'язаними комутаторами, кількість високоякісних оптичних модулів, необхідних для архітектури Spine-Leaf, у десятки разів перевищує кількість модулів для традиційної трирівневої архітектури, що збільшує загальну вартість розгортання. Однак це призвело до зростання ринку оптичних модулів, особливо для високошвидкісних оптичних модулів, таких як 100G та 400G.
Час публікації: 26 січня 2026 р.



